



Comparativa de IA que chatea con tus documentos
Cómo funcionan 4 herramientas y por qué son útiles para tu trabajo

Si ves a alguien con un embudo de papel de aluminio por la calle, problablemente sea yo.
Así he quedado después de maldecir, gruñir, arañar y aporrear a estas aplicaciones que te prometen sacarle todo el jugo a tus documentos.
Lo bueno es que tú te vas a librar de esta pelea ;)
🏃♀️ Si vas con prisa te lanzo un spolier rápido: Descarga Anything LLM y prueba su paso a paso.
Esto es lo que vas a encontrar en este envío:
🎯 El propósito
😈 ¿Qué demonios es un RAG?
🛡️ Comparativa para valientes
1️⃣ Custom GPTs o GPTs
2️⃣ Anything LLM
3️⃣ Embedchain
4️⃣ Robotito
🏁 Conclusión final
🍫 Tabla comparativa
🔥 ¿Quieres que haga un vídeo sobre este tema?
👉 Si llegamos a 40 me gustas en este envío (icono de ♥️) te lo grabo ;)
Soy Dani y esto es Programa con IA, una sección específica de la newsletter de Web Reactiva en la que hablamos de la aplicación de la inteligencia artificial al desarrollo de software (y a la vida digital).
👀 Si no te interesa, abajo del todo te cuento como deshacerte de ella sin perderte lo de cada domingo.
🎯 El propósito
Seguro que has probado ya alguna de esas extensiones que te deja “resumir un vídeo de YouTube” o “chatear con un PDF”.
Eso quería hacer pero con dos tipos de documentos muy diferentes:
Las transcripciones de 300 episodios de Web Reactiva (el podcast)
La documentación de la beta de Svelte 5
Habitualmente cuando hablas con ChatGPT o Gemini o cualquier modelo generativo (llamados en inglés LLM de “Large Language Models”) pasa algo como esto:
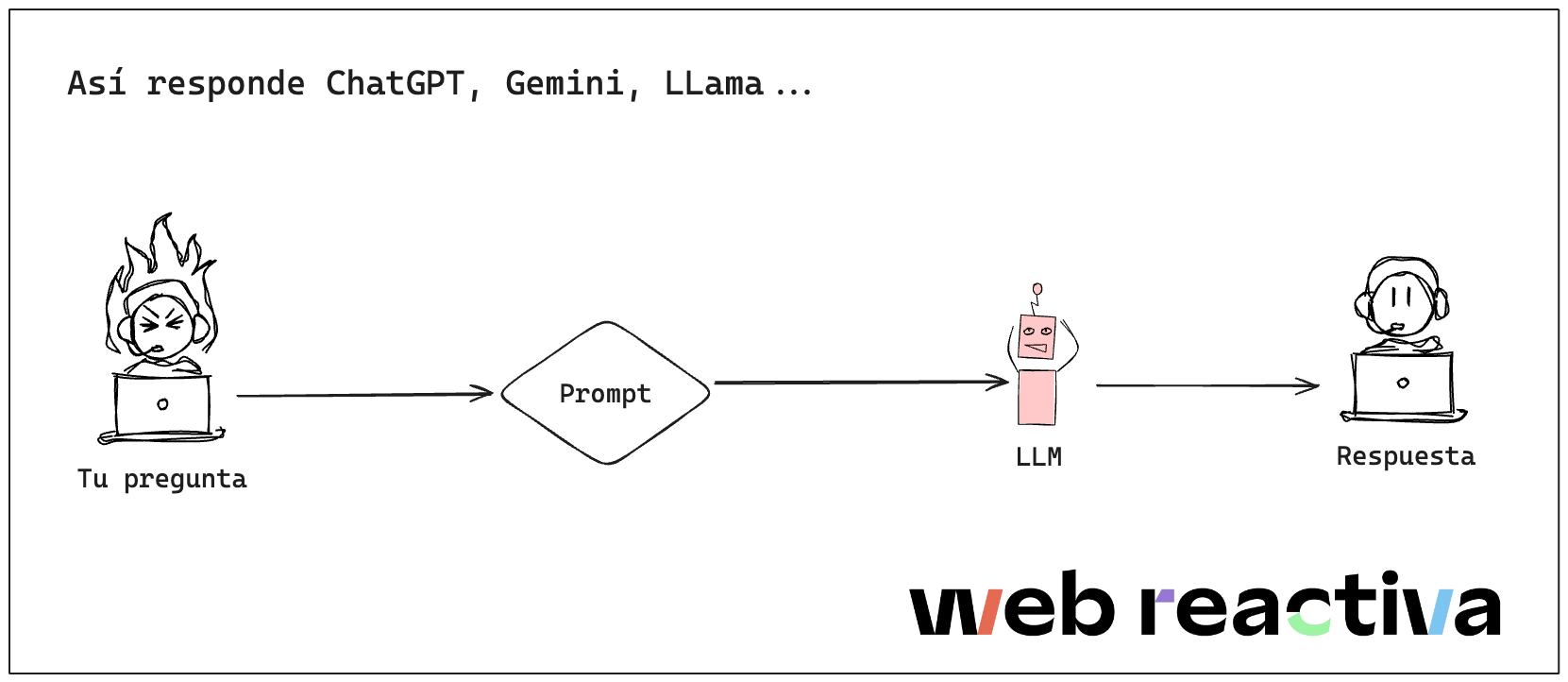
Tu pregunta se convierte en un “prompt” y el LLM busca entre su casi infinita sabiduría y te devuelve una respuesta “humana”.
😡 Casi infinita.
📝 Le falta conocer justo lo que te interesa. Tus cosas.
Así que gente muy lista se invento un término para, como siempre, confundirnos un poco más: el RAG.
😈 ¿Qué demonios es un RAG?
Son las siglas de “Retriever-Augmented Generation" (Generación Aumentada por Recuperación).
La idea detrás de RAG es mejorar la capacidad de los modelos de generación de texto para producir respuestas más informativas, precisas y relevante.
Así que incluimos a tu prompt un contexto extraído de la documentación sobre la que quieras que responda. Y añadimos más palabras raras, claro.
🔪 Splitting: Dividir cada documento en partes más pequeñas (más abajo te cuento por qué este paso es vital?
🧠 Embedding: Para poder realizar una búsqueda semántica necesitamos transformar nuestros documentos en vectores donde textos semánticamente similares están representados por vectores que están cerca entre sí.
💾 Vector Database: Esta es fácil, la base de datos donde guardamos esos vectores “embebidos”.
🔍 Similarity Search: Búsqueda en la base de datos de vectores para encontrar los fragmentos de texto más relevantes basándose en la similitud con el vector de la pregunta.
La pregunta que ahora hacemos al LLM la comparamos con los vectores que tenemos almacenados.
📝 De esta forma si preguntas por “manzanas” el sistema devolverá trozos de tu documentación que hablen de “manzanas”, “compota de manzana” y “apples” y no de “peras”.
🔥 ¿Tienes dudas sobre todo esto?
Pregunta en los comentarios (icono 💬) y deja un like, ¡gracias!
🛡️ Comparativa para valientes
Todos los sistemas que he probado tienen un esquema muy similar de funcionamiento.
Subimos los documentos.
Se lanza el proceso mágico del embedding.
Usamos el chat para hacer preguntas.
Se genera el prompt con el contexto extraído por la búsqueda.
El modelo generativo elegido genera la respuesta.
Aparecen adjuntas a esa respuesta las fuentes del contexto.
1️⃣ Custom GPTs o GPTs
Nos centramos en el sistema de ChatGPT para crear GPTs personalizados a la medida del usuario.
💬 Si eres usuario de ChatGTP Plus, puedes probar a preguntarle a Robotito GPT

👉 Un modelo muy similar es el de los Assistants de la API de OpenAI, pero ahí necesitarás crear un software intermedio para que el usuario pueda acceder a preguntar y obtener las respuestas. Por hoy, no lo metemos en la comparativa.
🛠️ Tipo
No Code en la parte de ChatGPT.
💶 Precio
20$ al mes.
🤖 Ecosistema
Solo tienes acceso a los modelos GPT 3.5 y GPT 4.
OpenAI ha creado toda una store para compartir de forma pública (y también privada) el acceso a estos bots.
El código es propietario con lo que no ves como funciona por debajo.
📚 Aprendizajes
Permite crear un “bot” personalizado con sus propias características de tono, formato de respuesta, longitud de la misma.
En ocasiones se recupera los datos con un proceso similar al explicado más arriba y en otros se lanza el analizador de código para buscar la información.
Permite añadir hasta 10 ficheros, pero los foros están llenos de preguntas sobre esto.
A mi no me dejó subir un JSON de 10,8 MB y tuve que trocearlo.
Cuanto más precisa sea la documentación aportada, mejor y más rápida es la respuesta.
📲 Conclusión
Solo los usuarios de pago de ChatGPT pueden usarlo. Superado ese obstáculo es una conversación idéntica a la que sueles tener con “gepeto”.
2️⃣ Anything LLM
Su objetivo es ponerlo fácil y que tengas algo parecido a lo de los GPTs pero moldeado con una larguísima lista de herramientas integradas, muchas de ellas gratuitas.

🛠️ Tipo
No Code, es una aplicación de escritorio que puedes instalar en Windows y Mac. También puede arrancarse con Docker.
💶 Precio
Gratis para la aplicación y los modelos que sean open source.
🤖 Ecosistema
Se engancha con una infinidad de herramientas. Creo que incluso son demasiadas.
Desde las API de pago de OpenAI, Anthropic o Mistral hasta los LLM open source que usas en Ollama, LMStudio o LocalAI.
La misma riqueza se repite en los “embedders” y en las “vector database”. De hecho, de serie, Anything LLM incluye una de cada sin necesidad de configuración.
📚 Aprendizajes
Aparecen las referencias a los documentos del contexto para dar respuesta pero no puedes elegir cómo trocearlos ni el metadata añadido a cada fragmento.
Te deja añadir control multiusuario y ajustes básicos para cada “gepeto” que crees.
Si quieres acceder a la API del backend necesitas arrancarlo con Docker o con el código de desarrollo.
En un Mac Mini M1 puede bien con 10MB de fichero, pero en el MacBook de 2020 es imposible.
📲 Conclusión
La interfaz no es un 10 pero es el más fácil para usar ya mismo. La experiencia de usuario dependerá de la velocidad de tu computadora.
Eso sí, es un proyecto muy activo en Github.
3️⃣ Embedchain
Un framework para developers que quieren saltarse toda la parte de crear conexiones entre herramientas e ir directos al grano.
🛠️ Tipo
SiCode. Es un frameowrk que trabaja sobre FastAPI (Python) en su parte backend y Streamlit o Next.js en la parte de front.
💶 Precio
Open Source.
🤖 Ecosistema
Alimenta al RAG con todo tipo de fuentes, algunas muy curiosas: YouTube, Substack, sitemaps de webs, Notion o Dropbox.
Una lista muy similar a la de Anything LLM con una lista prolija de herramientas open source y de pago.
Las piezas del “embedder” y la “vector database” las incorpora de serie el framework. Usa SQLite como base de datos.
📚 Aprendizajes
Todo se hace por código, aunque la documentación no es demasiado clara en algunos puntos.
Lo mejor es pasarse por la carpeta examples y probar su “chat pdf” o la integración “full stack”.
Casi escondido tienen un sistema gratuito para poder enganchar tu conocimiento con las “actions” de los GPTs.
📲 Conclusión
Recomiendo la instalación basada en Docker, libre de problemas de versiones de librerías.
Es la más difícil de todas porque es muy ambiciosa y, aunque camina a hombros de gigantes, se nota que no todo está probado y funcional.
4️⃣ Robotito
Es unan versión completamente personalizada creada con Next.js, OpenAI y Langchain, el gran framework para trabajar con modelos generativos (y que está detrás de casi todos los proyectos que has visto).
🤖 Pregúntale a Robotito por React o por lo que quieras
🛠️ Tipo
Está todo programado a medida. Puedes ver sus clones en Creando Newsletters de
y PinguBot de .💶 Precio
Gratis para ti. A nosotros nos cobra por petición a la API de OpenAI tanto cuando aportamos la documentación como al generar las respuestas.
🤖 Ecosistema
En el momento del desarrollo el único proveedor fiable era OpenAI y lo usamos tanto para el “embedding” como para el LLM con GPT-3.5.
📚 Aprendizajes y 📲 Conclusión
Lo conté en detalle en este vídeo de introducción a la masterclass: Cómo crear aplicaciones con Inteligencia Artificial con LangChain y OpenAI

🏁 El remate y conclusión final
1️⃣ Está todo en pañales.
Es cierto que la llegada de los GPTs de ChatGPT le dieron un buen empujón a los RAG, pero aún queda mucho camino por recorrer.
2️⃣ Lo más importante: Trocea la documentación.
El proceso de “splitting” es esencial para obtener la mayor precisión posible en las respuestas.
Cuando no puedas controlar como se hace, sube documentos con un formato claro y por separado. Los GPTs, por ejemplo, entienden como contexto el nombre de los ficheros.
🔥 Añade metadata a cada corte. En mi caso todo mejoró mucho añadiendo referencias al título y la URL de cada podcast en mi caso.
3️⃣ Los modelos más evolucionados funcionan mejor.
Mis pruebas con Mistral o LLama están bien, pero no alcanzan la capacidad de respuesta de GPT-4.
Queda la puerta abierta a probar Gemini y Mistral, claro :)
🍫 Tabla comparativa

☝️ Algo que puedes hacer antes de marcharte
🧡 Llegar a más de 40 “me gustas” en esta newsletter no es un capricho.
Es una forma de contarle al algoritmo que esto mola. Haz clic en el “corazón ♥️”
Y, como premio, me pongo las pilas y grabo un vídeo explicando cómo hacer funcionar el RAG.
👉 ¿Tienes dudas? Pregunta en los comentarios (icono )💬
👉 Si quieres dejar de recibir estos envíos de Programa con IA aquí te explico como. (Claro que yo te aconsejo que no lo hagas ;)
PD: Si compartes esta newsletter por ahí, te abrazo fuerte. En Whatsapp o con este botón
Post muy interesante y didáctico, Dani! Una duda: el Similarity Search, ¿quién lo hace? ¿un LLM más pequeño?
Pedazo de comparativa 🤩
La opción de “a medida” está genial por lo fácil que es para el usuario pero es cierto que para los que nutrimos la bbdd puede ser un poco c*ñazo por el proceso que hay que seguir (especialmente para no developers como yo)
¡Gracias por abanderar nuestros Robotitos!